
Node.js/JavaScriptとPuppeteerを使用し、Amazon(アマゾン)をスクレイピングすることについて解説しています。
なお、JavaScriptの実行にはNode.jsとnpm(Node Package Manager)を使用するので、コンピュータにNode.jsとnpmがインストールされている必要があります。
■PC環境
・Windows10、Administrator(管理者)アカウント
・node –version v14.15.0
・npm –version 6.14.8
■空のディレクトリを用意する

まずはWindows10上に空のディレクトリを用意します。今回は「C:\Users\Administrator(フォルダパス)」に「web_scraping」というディレクトリを用意しました。
■package.json(初期値)を作成する
用意したあとに、Windows10の検索ボックスで「cmd」と入力し、コマンドプロンプトをクリックします。クリックすると、コマンドプロンプトが起動します。
C:\Users\Administrator>cd web_scraping
上記のコマンドを入力し、Enterキーを押します。cdコマンドでディレクトリに移動します。
C:\Users\Administrator\web_scraping>npm init -y
移動後、上記のコマンドを入力し、Enterキーを押します。package.json(初期値)を作成します。
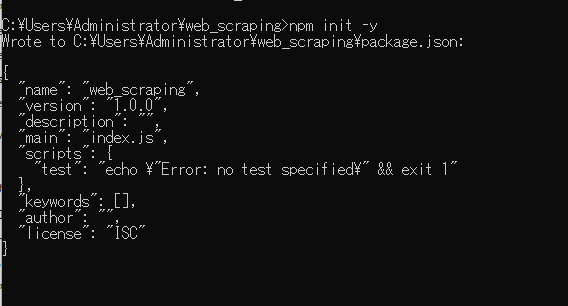
Enterキーを押すと、package.jsonが作成され、package.jsonの中身が出力されます。
■Puppeteerのインストール
C:\Users\Administrator\web_scraping>npm install puppeteer
出力後、上記のコマンドを入力し、Enterキーを押します。
> puppeteer@9.0.0 install C:\Users\Administrator\web_scraping\node_modules\puppeteer > node install.js Downloading Chromium r869685 - 166.1 Mb [====================] 100% 0.0s Chromium (869685) downloaded to C:\Users\Administrator\web_scraping\node_modules\puppeteer\.local-chromium\win64-869685 npm notice created a lockfile as package-lock.json. You should commit this file. npm WARN web_scraping@1.0.0 No description npm WARN web_scraping@1.0.0 No repository field. + puppeteer@9.0.0 added 54 packages from 72 contributors and audited 54 packages in 45.876s 8 packages are looking for funding run `npm fund` for details found 0 vulnerabilities
Enterキーを押すと、インストールが開始され、完了となります。
■スクリプトを作成する
完了後、スクリプトを作成するために、「C:\Users\Administrator(フォルダパス)」の「web_scraping」ディレクトリ内に「scrapers.js」というjsファイルを作成します。作成後、このファイルをコードエディタで開きます。
■コード(scrapers.js)
const puppeteer = require('puppeteer');
async function scrapeProduct(url){
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const [el] = await page.$x('//*[@id="productTitle"]');
const txt = await el.getProperty('textContent');
const rawTxt = await txt.jsonValue();
console.log({rawTxt});
browser.close();
}
scrapeProduct('https://www.amazon.co.jp/商品詳細ページ');Webブラウザでアマゾン(https://www.amazon.co.jp/)の商品詳細ページにアクセスし、ページ内の要素を取得し、コンソールに要素内のテキストを出力します。今回は商品のタイトルを取得して出力してみます。
■ページ内の特定要素(Xpath)を取得する場合
アマゾン(https://www.amazon.co.jp/)のページ内の特定要素(Xpath)を取得する場合は、GoogleChrome上で取得した要素にマウスを移動し選択します。
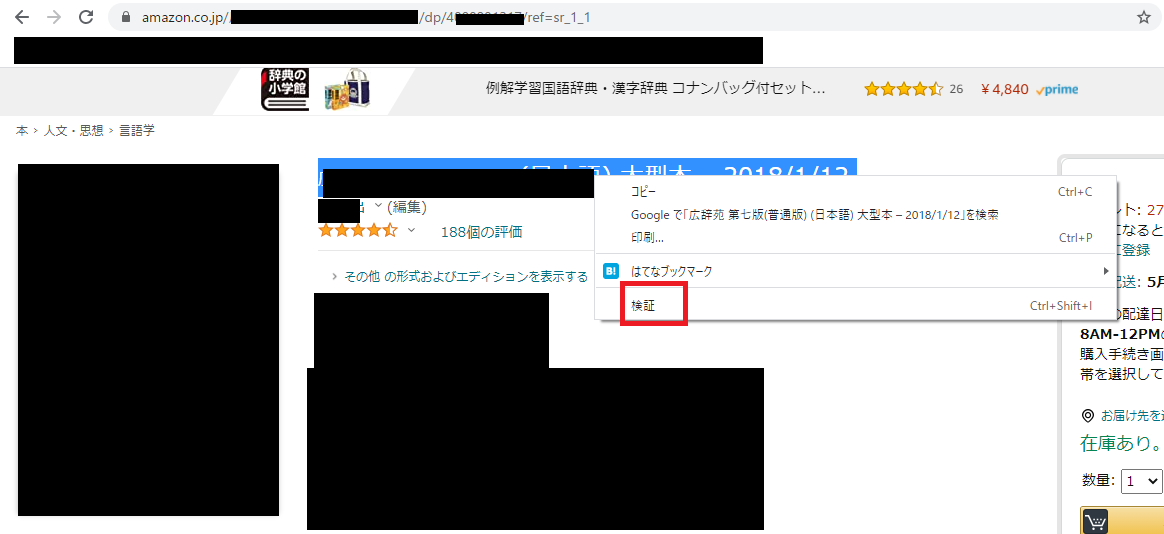
選択後、右クリックします。クリックすると、メニューが表示されますので、この中から「検証」をクリックします。
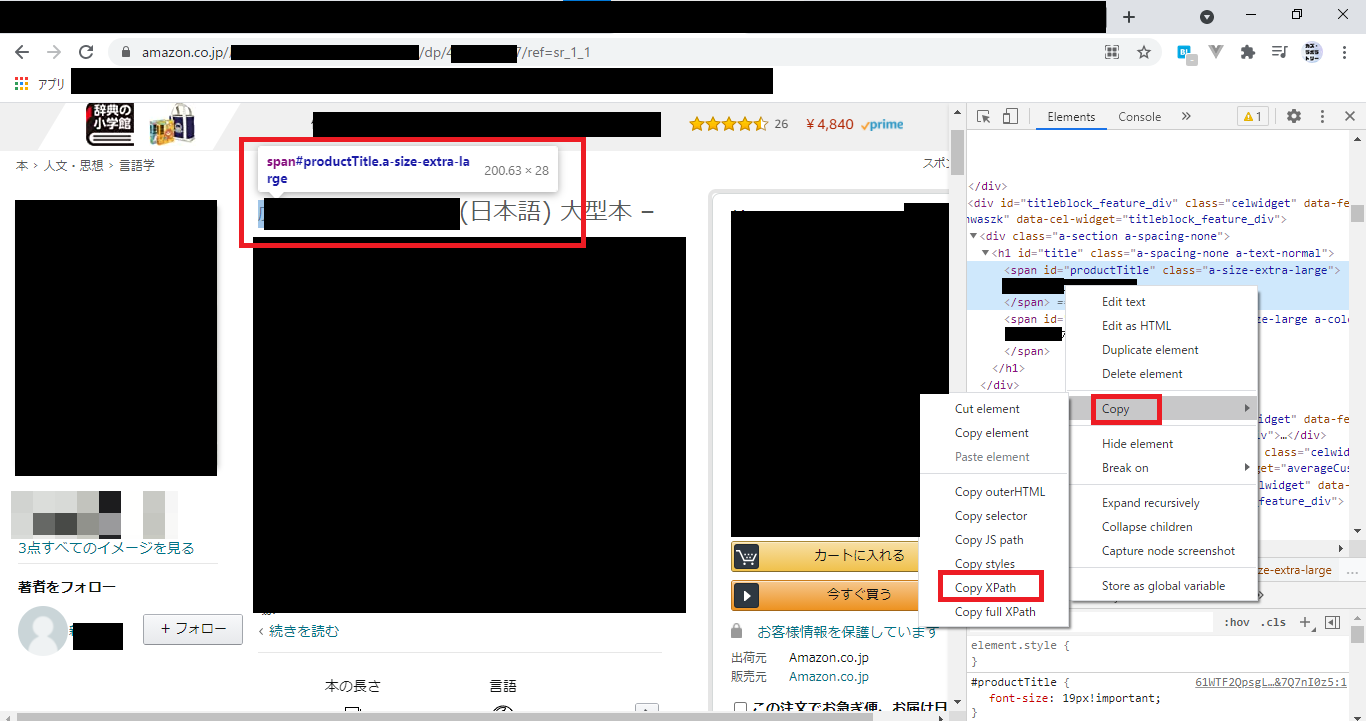
クリックすると、右側にWebページのソースが表示され、選択した部分が水色に表示されます。この状態で右クリックします。すると、メニューが表示され「Copy」をクリックします。さらにメニューが表示されますので「Copy Xpath」をクリックします。
クリックすると、特定要素(Xpath)がコピーされますので、あとはコードエディタへ追加します。
■実行
スクリプトが完成した後は、実際にAmazon(アマゾン)をスクレイピングできるのか検証のため、実行させてみます。今回は、コマンドプロンプトから実行してみます。
C:\Users\Administrator\web_scraping>node scrapers.js
実行する際は、上記のコマンドを入力し、Enterキーを押します。

Enterキーを押すと、ブラウザが自動的に起動し、今回指定したアマゾン(https://www.amazon.co.jp/)の商品詳細ページにアクセスし、ページ内の特定要素を取得し、出力させることができました。

コメント