
Pythonでspacyを使用し、日本語の単語の区別と品詞のタグ付けをしてみます。
今回は、高度な自然言語処理用「spacy」をインストールして行います。spacyはPythonの標準ライブラリではありませんので、事前にインストールする必要があります。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■spacyを使用し、日本語の単語の区別と品詞のタグ付けをする
では、早速、spacyを使用し、日本語の単語の区別と品詞のタグ付けをするスクリプトを書いていきます。
■コード
from spacy.lang.ja import Japanese
nlp = Japanese()
doc = nlp("私は午前10時に田中さんと大阪市内のカフェで待ち合わせです。")
for Word in nlp(doc):
print(Word.text, Word.lemma_, Word.tag_, Word.pos_)今回は、日本語の単語のセグメンテーション(区別)と品詞のタグ付けのために、日本語形態素解析器であるSudachiPyを使用します。「nlp = Japanese()」でSudachiPyの分割モードAを使用できます(デフォルト)。
doc変数を定義し、nlp()を用いて、日本語の単語のセグメンテーション(区別)と品詞のタグ付けを行うために、日本語の文章を渡します。
そして、日本語形態素解析の結果(text(テキスト),基本形(lemma_), 品詞(pos_),品詞(tag_))を出力してみます。
■実行・検証
このスクリプトを「sl_test.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
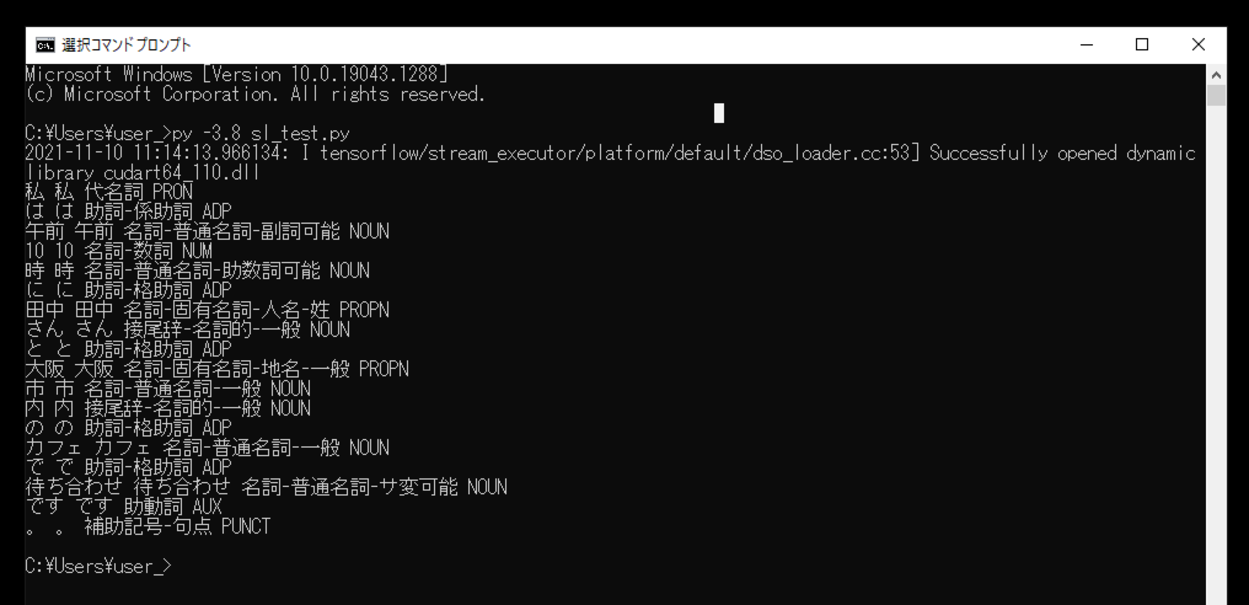
2021-11-10 11:14:13.966134: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cudart64_110.dll 私 私 代名詞 PRON は は 助詞-係助詞 ADP 午前 午前 名詞-普通名詞-副詞可能 NOUN 10 10 名詞-数詞 NUM 時 時 名詞-普通名詞-助数詞可能 NOUN に に 助詞-格助詞 ADP 田中 田中 名詞-固有名詞-人名-姓 PROPN さん さん 接尾辞-名詞的-一般 NOUN と と 助詞-格助詞 ADP 大阪 大阪 名詞-固有名詞-地名-一般 PROPN 市 市 名詞-普通名詞-一般 NOUN 内 内 接尾辞-名詞的-一般 NOUN の の 助詞-格助詞 ADP カフェ カフェ 名詞-普通名詞-一般 NOUN で で 助詞-格助詞 ADP 待ち合わせ 待ち合わせ 名詞-普通名詞-サ変可能 NOUN です です 助動詞 AUX 。 。 補助記号-句点 PUNCT
実行すると、今回指定した日本語の文章内で、日本語形態素解析器を利用し、単語のセグメンテーション(区別)と品詞のタグ付けが行われて、結果を出力させることができました。

コメント