
PythonでWebページのコンテンツを取得してみます。
Webページのコンテンツを取得するためには、http.clientモジュールを使用します。http.clientモジュールは、Pythonの標準ライブラリですので、事前にインストールする必要はありません。
■Python
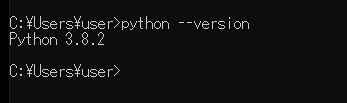
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■http.clientモジュールを使用してWebページのコンテンツを取得する
では、早速http.clientモジュールを使用してWebページのコンテンツを取得するスクリプトを書いていきます。
■コード
import http.client
h = http.client.HTTPConnection("www.kazuuu.net")
h.request("GET","/")
data= h.getresponse()
text= data.readlines()
for t in text:
print(t.decode('utf-8'))http.clientモジュールをインポートで呼び出して、hという変数を作成し、http.client.HTTPConnection()関数で、Webサイト(今回はwww.kazuuu.net)をホストするサーバーへの接続を行います。
次にWebサイト(今回はwww.kazuuu.net)をホストするサーバーへの接続を行い、request()関数でGETリクエストを実行し、Webページから情報を取得します。
取得後、getresponse()関数でWebサイトのすべてのデータを取得し、dataという変数に収納します。
収納後、textという変数を作成し、data変数で収納したリストの全行読み込みます。
読み込んで収納したtext変数を、forループを使用して各行をループし、decode()関数で文字コードを「utf-8」に変換します。変換後、print関数で出力してみます。
■実際
今回のスクリプトを「webpage_content_acquisition.py」という名前で保存し、コマンドプロンプトから実行してみます。
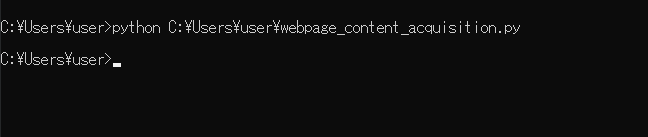
実行すると、print関数の記述をしたのですが、何も出力されません。
■httpsプロトコルで接続する
何も出力されない原因は、
h = http.client.HTTPConnection("www.kazuuu.net")上記のコードに原因があります。今回接続を試みたWebサイトのURLを確認すると、「https://www.kazuuu.net/」となっており、HTTPではなく「HTTPS」です。
これが原因でスクリプトを実行したときに何も出力されませんでした。この問題を解決するためには、httpプロトコルで接続することから、httpsプロトコルで接続することに変更する必要があります。
変更する場合は今回のスクリプトのコードを変更します。
■コード
import http.client
h = http.client.HTTPSConnection("www.kazuuu.net")
h.request("GET","/")
data= h.getresponse()
text= data.readlines()
for t in text:
print(t.decode('utf-8'))http.client.HTTPConnection関数を、http.client.HTTPSConnection関数に変更します。
■実行
スクリプトを変更し、コマンドプロンプトから実行してみます。
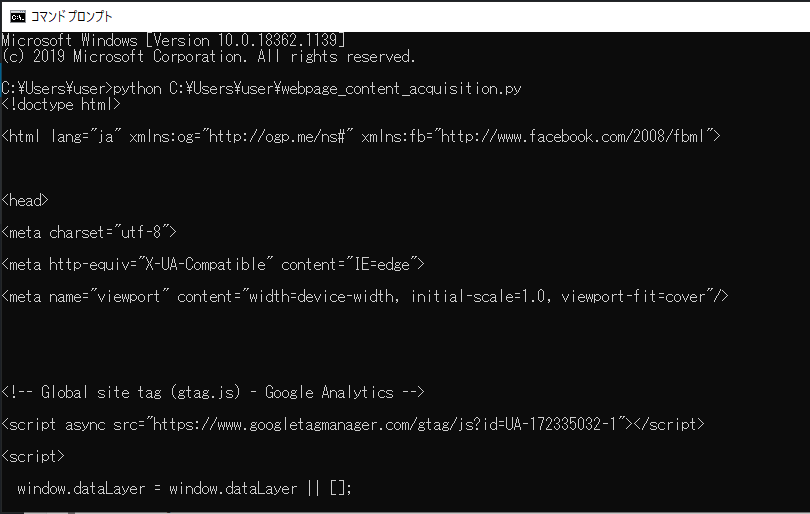
実行してみると、Webページのコンテンツを取得されてprint関数で出力されることが確認できました。

コメント