
mechanizeを使用してPythonでWebサイトのタイトルを出力してみます。
mechanizeモジュールは、Pythonの標準ライブラリではありませんので、事前にインストールしておく必要があります。
■Python
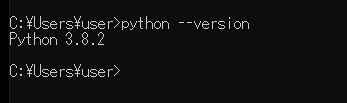
今回のPythonのバージョンは、「3.8.2」を使用しています。(Windows10)
■mechanizeを使用してWebサイトのタイトルを出力する
では早速、mechanizeを使用してWebサイトのタイトルを出力するスクリプトを書いていきます。
■コード
import mechanize url ='https://www.yahoo.co.jp/' op = mechanize.Browser() op.open(url) print(op.title())
インポートで、mechanizeモジュールを呼び出して、urlという変数を作成し、タイトルを出力したいWebサイトのURLを指定します。今回は「Yahoo!Japan」のタイトルを出力してみます。
次に、opという変数を作成し、mechanizeBrowserオブジェクトを収納します。その後、open()で指定したURLをmechanizeBrowserオブジェクトで開きます。
開いた後に、title()でWebサイトのタイトルを出力します。
■実行
今回書いたスクリプトを「website_title.py」という名前で保存し、コマンドプロンプトから実行してみます。
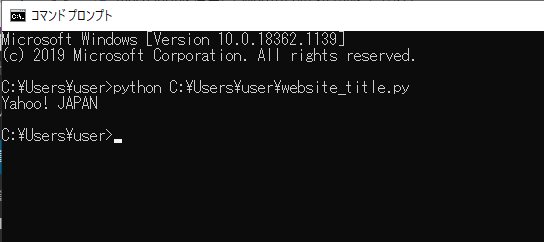
実行してみると、今回指定したWebサイトのタイトルが出力されました。
■HTTP Error 403: b’request disallowed by robots.txt’というエラーが発生する場合
今回、指定したWebサイトのタイトルが出力されましたが、Google.comでもタイトルが出力されるのか検証を行いました。
mechanize._response.httperror_seek_wrapper: HTTP Error 403: b’request disallowed by robots.txt’
スクリプトを実行すると、上記のエラーが発生しました。「HTTPエラー403:リクエストはrobots.txtによって許可されていません」という内容でGoogle.com側のrobots.txtの影響でスクレイピングがブロックされる。なお、これはサーバが「HTTP 403エラー」を返したのではなく、robots.txtファイルの解析に基づいてクライアント(Google)から作成された403。
■コード
import mechanize
url ='https://www.google.com/'
op = mechanize.Browser()
op.set_handle_robots(False)
op.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
op.open(url)
print(op.title())robots.txtによって許可されていない場合は上記を試みるとWebサイトのタイトルを出力できる。set_handle_robots()で、robots.txtをオフ(off)にできます。
■実行
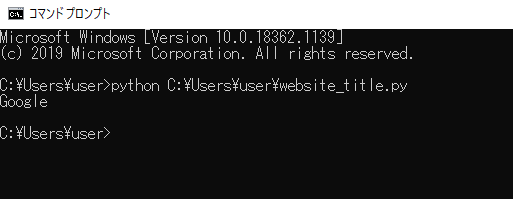
実行してみると、「HTTP Error 403: b’request disallowed by robots.txt’」というエラーは表示されず、Webサイトのタイトルを出力することができました。

コメント