
JavaScript / Node.jsでWebクローラーを作り、Webスクレイピングを行ってみます。
なお、JavaScriptの実行にはNode.jsとnpm(Node Package Manager)を使用するので、コンピュータにNode.jsとnpmがインストールされている必要があります。
■PC環境
・Windows10、Administrator(管理者)アカウント
・node –version v14.15.0
・npm –version 6.14.8
■新規フォルダの作成と、crawler.jsという空のファイルを作成する
まずは、新規フォルダの作成と、crawler.jsという空のファイルを作成します。
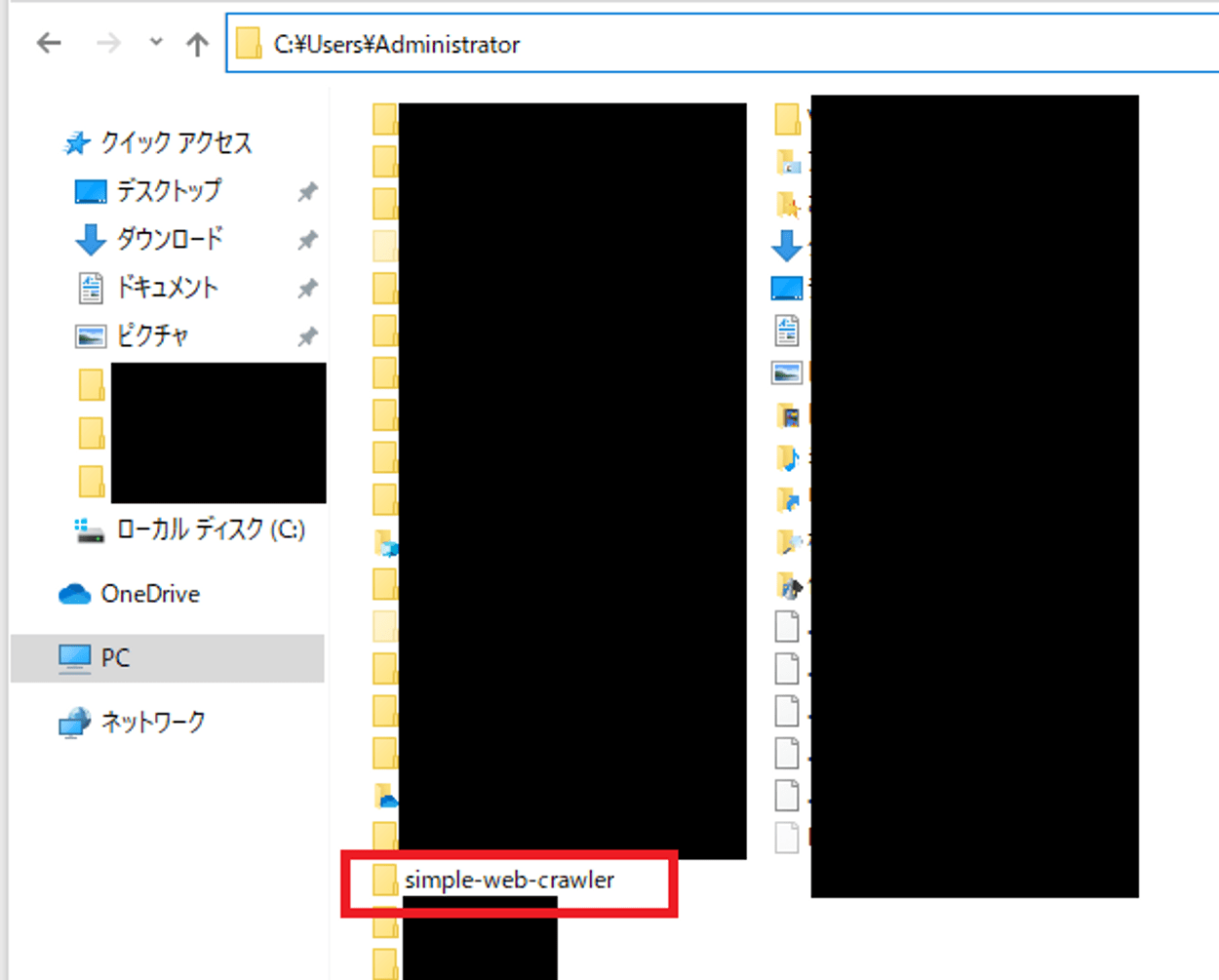
今回は「C:\Users\Administrator(フォルダパス)」という場所に、「simple-web-crawler」という名前のフォルダを作成します。
■コード
var request = require('request');
var cheerio = require('cheerio');
var URL = require('url-parse');作成後、コードエディタを開き、上記のコードを記述します。
なお、今回は、下記の3つのライブラリを使用します。
・Request(HTTPリクエストを行う)
・Cheerio(ページ上のHTML要素を解析して選択する)
・URL-parse(URLを解析する)
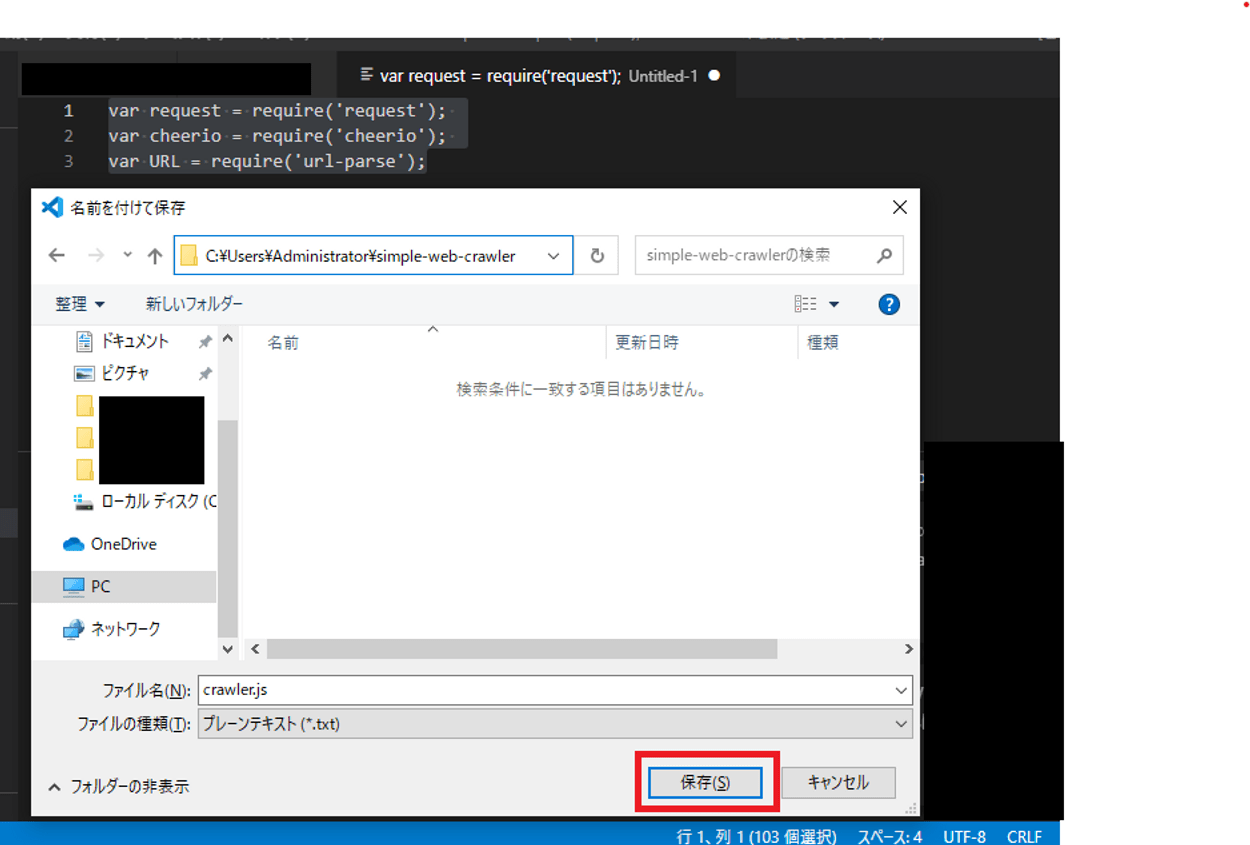
記述後、ファイルを保存します。保存する際に、「crawler.js」という名前でファイルを保存します。保存する場所は、「C:\Users\Administrator」の「simple-web-crawler」というフォルダになります。
■npmを使用し、ライブラリをインストールする
保存後、npmを使用し、ライブラリをインストールしますが、その前にpackage.jsonというファイルを作成し、今回のプロジェクトの説明と依存関係を指定します。
■コード
{
"name": "simple-webcrawler-javascript",
"version": "0.0.0",
"description": "A simple webcrawler written in JavaScript",
"main": "crawler.js",
"author": "Stephen",
"license": "ISC",
"dependencies": {
"cheerio": "^0.19.0",
"url-parse": "^1.0.5",
"request": "^2.65.0"
}
}そのために、コードエディタを開き、上記のコードを記述します。
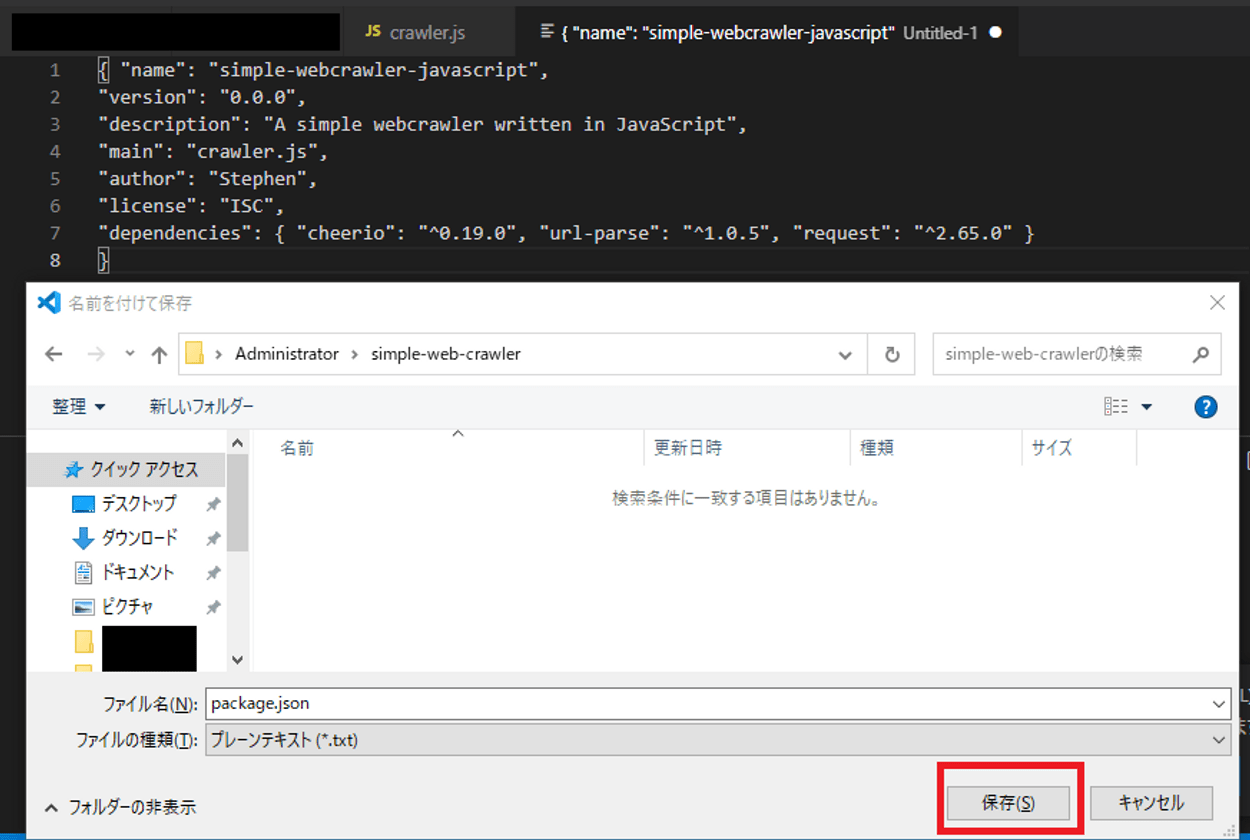
記述後、ファイルを保存します。保存する際に、「package.json」という名前でファイルを保存します。保存する場所は、「C:\Users\Administrator」の「simple-web-crawler」というフォルダになります。
保存後、Windows10の検索ボックスで「cmd」と入力し、コマンドプロンプトをクリックします。クリックすると、コマンドプロンプトが起動します。
C:\Users\Administrator>cd simple-web-crawler
起動後、上記のコマンドを入力し、「C:\Users\Administrator」の「simple-web-crawler」というフォルダに移動するために、エンターキーを押します。
C:\Users\Administrator\simple-web-crawler>npm install
npm WARN deprecated request@2.88.2: request has been deprecated, see https://github.com/request/request/issues/3142 npm WARN deprecated har-validator@5.1.5: this library is no longer supported npm notice created a lockfile as package-lock.json. You should commit this file. npm WARN simple-webcrawler-javascript@0.0.0 No repository field. added 68 packages from 68 contributors and audited 68 packages in 4.328s 2 packages are looking for funding run `npm fund` for details found 4 vulnerabilities (2 low, 2 high) run `npm audit fix` to fix them, or `npm audit` for details
エンターキーを押すと、ライブラリのインストールが開始され、上記のようなメッセージが表示されます。今回はライブラリが古いので、脆弱性が見つかりましたなどの表示がありますが、テストで動作確認を行うため、脆弱性が見つかりましたなどは、いったん無視し進めます。
■JavaScriptでのWebページの取得と解析
ライブラリをインストール後、JavaScriptでのWebページの取得と解析を行います。行う場合は、コードエディタで「C:\Users\Administrator」の「simple-web-crawler」というフォルダの「crawler.js」を開き、Webページの取得と解析を行うコードを記述します。
■コード
var request = require('request');
var cheerio = require('cheerio');
var URL = require('url-parse');
var pageToVisit = "https://www.yahoo.co.jp/";
console.log("閲覧ページ: " + pageToVisit);
request(pageToVisit, function(error, response, body) {
if(error) {
console.log("Error: " + error);
}
// ステータスコードの確認 (200はHTTP OK)
console.log("ステータスコード: " + response.statusCode);
if(response.statusCode === 200) {
// ソース内のdocumentのbodyを解析
var $ = cheerio.load(body);
console.log("ページタイトル: " + $('title').text());
}
});記述するコードは上記になります。今回はYahoo!Japan(https://www.yahoo.co.jp/)のページの取得と解析を行ってみます。
記述後、このコードを「crawler.js」に上書き保存します。
■実行
保存後、JavaScriptでのWebページの取得と解析を行うため、スクリプトを実行してみます。
実行する際は、Windows10の検索ボックスで「cmd」と入力し、コマンドプロンプトをクリックします。クリックすると、コマンドプロンプトが起動します。
C:\Users\Administrator>cd simple-web-crawler
起動後、上記のコマンドを入力し、「C:\Users\Administrator」の「simple-web-crawler」というフォルダに移動するために、エンターキーを押します。
C:\Users\Administrator\simple-web-crawler>node crawler.js
押した後、上記のコマンドを入力し、エンターキーを押します。

エンターキーを押すと、今回指定したYahoo!Japan(https://www.yahoo.co.jp/)をWebクローラーが収集(クローリング)を行い、「ステータスコード:200(リクエストが成功)」となり、「ページタイトル」を取得することができました。

コメント