
PythonでBoto3を用いてAmazon Textract(AWS Textract)を使用してみます。Textractは、スキャンされたドキュメントからテキスト、手書き、データを自動的に抽出する機械学習サービスのこと。
ちなみに、今回はBoto3を用います。このライブラリ・モジュールは、Pythonの標準ライブラリではありませんので、事前にインストールする必要があります。また、Boto3を用いる場合には、クレデンシャル(資格情報)などの設定が必要になりますので、こちらを参考にしていただければと思います。
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■画像を用意する
Boto3を用いてAWS Textractを使用してみますが、その前にTextractを用いてスキャンする画像を用意します。
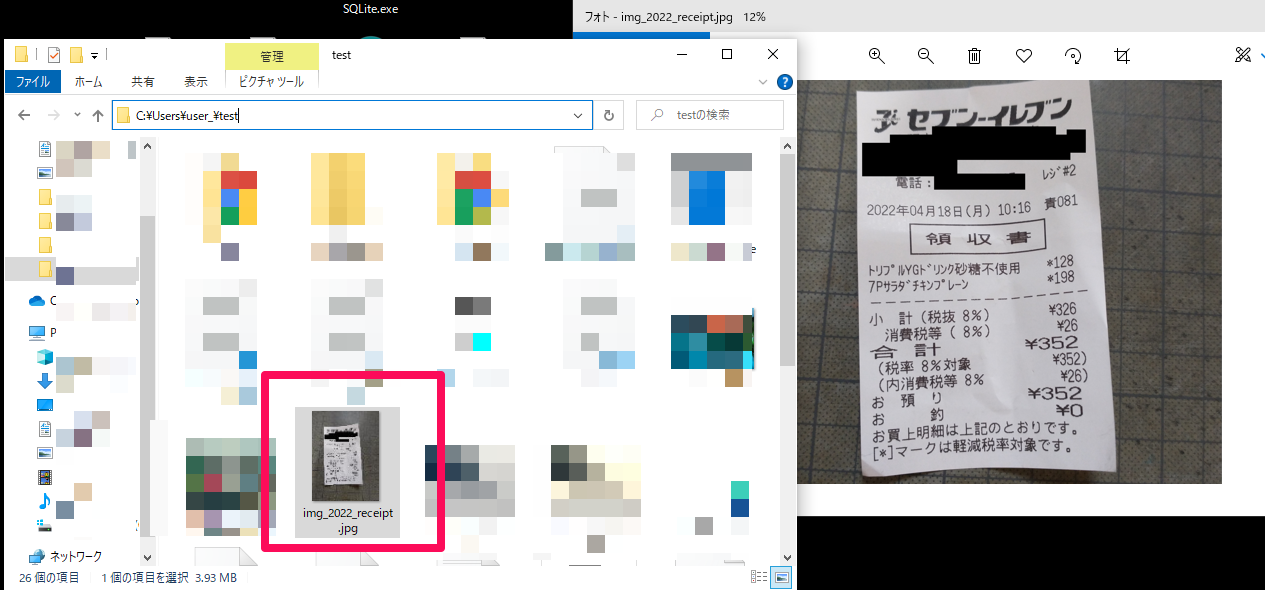
今回はjpg形式の日本語表記のレシートを用意しました。ファイルの名前は「img_2022_receipt.jpg」で、ファイルが置かれている場所は「C:\Users\user_\test(フォルダパス)」となります。
■Boto3を用いてAWS Textractを使用する
画像の用意ができましたので、Boto3を用いてAWS Textractを使用し画像の文字を抽出するスクリプトを書いていきます。
■コード
import boto3
client = boto3.client('textract')
with open(r'C:\Users\user_\test\img_2022_receipt.jpg','rb') as file:
img_test = file.read()
bytes_test = bytearray(img_test)
response = client.analyze_document(Document={'Bytes':bytes_test},FeatureTypes=['TABLES'])
print(response)importでboto3を呼び出します。その後、clientという変数を定義し、その中でboto3.client()を用います。括弧内には第1の引数,パラメータとしてtextractを渡します。これで低レベルのサービスクライアントが作成されます。
クライアントを作成語、with構文を用いて、さらにopen()を用いてます。括弧内の引数,パラメータとして今回用意した画像ファイルの名前と置かれている場所を渡します。開いた画像の情報をfile変数に格納します。格納後、img_test変数を定義し、その中でread()を用いてます。括弧内の引数,パラメータとしてfile変数を渡します。これで画像の情報が読み込まれます。
その後、bytearray()を用います。括弧内の引数,パラメータとしてimg_test変数を渡します。これでimg_test変数をバイト配列に変換します。
次にresponseという変数を定義し、その中でclient.analyze_document()を用います。括弧内には、第1の引数,パラメータとして、「Document = {‘Bytes’:bytes_test}」を渡します。今回スキャンを行うドキュメントがバイト配列に変換された画像ファイルであることをしめす。第2の引数,パラメータとして、「FeatureTypes=[‘TABLES’]」を渡します。これでtextractから構造データを検出します。
最後に、スキャンされた画像ファイルから抽出されたテキストをprint()で出力します。
■実行・検証
このスクリプトを「test_ocr_a.py」という名前で、Pythonが実行されている作業ディレクトリ(カレントディレクトリ)に保存し、コマンドプロンプトから実行してみます。
{‘DocumentMetadata’: {‘Pages’: 1}, ‘Blocks’: [{‘BlockType’: ‘PAGE’, ‘Geometry’: {‘BoundingBox’: {‘Width’: 0.5882643461227417, ‘Height’: 0.6812906861305237, ‘Left’: 0.17425720393657684, ‘Top’: 0.14329953491687775}, ‘Polygon’: [{‘X’: 0.17425720393657684, ‘Y’: 0.17430026829242706}, {‘X’: 0.7017901539802551, ‘Y’: 0.14329953491687775}, {‘X’: 0.762521505355835, ‘Y’: 0.815534770488739}, {‘X’: 0.18705542385578156, ‘Y’: 0.8245902061462402}]}, ‘Id’: ‘b3865930-f85c-4ac3-8f64-6ed13ff34f96’, ‘Relationships’: [{‘Type’: ‘CHILD’, ‘Ids’: [‘36111e82-61e2-468d-87c3-431ac8f6beec’, ‘db2557cb-efdb-4854-b39e-8d981335dae7’, ‘d3ed1758-c7f9-4c00-b9cd-2b585886cdea’, ‘4873fc3f-7869-4a2a-a33d-83ced8836a57’, ‘893a57ed-0d82-474d-b396-8beb64bba52a’, ‘dbc48b59-c4e4-426b-8de9-8fa517266cf8’, ‘a650c55e-e872-4dd9-8c25-344024dd553b’, ‘11351405-bf89-4b70-930d-a6865da6bbbd’, ’64c8658a-6ad0-497e-a01c-854796e43364′, ‘fc87c469-b916-4c2a-8c36-e685a2380bbe’, ‘1d43ecc5-31d8-40d2-bedb-e3852180b794’, ‘7fdce02e-ce95-4f21-8aca-812763fb66c5’, ‘539f64b7-ad85-4ac7-93c8-21a49df15c9c’, ‘699468a0-8ef4-453f-8d90-351a680920d2’, ‘163cddf7-254e-485f-9bb3-dcba662ea4b5’, ‘633e7df6-1bdc-467b-81dc-05f7b5eaa538’, ‘5d5affe1-7ed6-4cf5-b85c-5006f63d75f4’, ‘7b12d7c6-fa45-4075-9df7-0e3fa12364a1’, ‘534ce5a5-137f-4241-ae80-a4e9de10166e’, ‘d81327d2-9294-47a4-8838-22b95ccc4081’, ‘c1659e6f-381f-4186-961f-83e6987e13ea’, ‘492f2c3d-5814-4f9e-8e8e-45f22c6919d8’, ‘9d87ab7e-2bd6-4f9a-986f-c4173bdd0077’, ‘a1dd2439-8f74-4a93-aca8-86f1a5183316′, ’92fafb22-1cf3-43af-b9fc-036512b01d46’]}]}, {‘BlockType’: ‘LINE’, ‘Confidence’: 26.142662048339844, ‘Text’: ’13:#2′, ‘Geometry’: {‘BoundingBox’: {‘Width’: 0.07951237261295319, ‘Height’: 0.03136906772851944, ‘Left’: 0.5942871570587158, ‘Top’: 0.2965908348560333}, ‘Polygon’: [{‘X’: 0.5942871570587158, ‘Y’: 0.3003769814968109}, {‘X’: 0.6714569330215454, ‘Y’: 0.2965908348560333}, {‘X’: 0.6737995147705078, ‘Y’: 0.3242975175380707}, {‘X’: 0.596339225769043, ‘Y’: 0.32795992493629456}]}, ‘Id’: ‘36111e82-61e2-468d-87c3-431ac8f6beec’, ‘Relationships’: [{‘Type’: ‘CHILD’, ‘Ids’: [’51a4f0e9-2b9e-4041-994f-7b4e5960a76a’]}]}, {‘BlockType’: ‘LINE’, ‘Confidence’: 65.34114837646484, ‘Text’: ‘(A) 10:16 3081’, ‘Geometry’: {‘BoundingBox’: {‘Width’: 0.25130465626716614, ‘Height’: 0.043759074062108994, ‘Left’: 0.42613205313682556, ‘Top’: 0.3486822843551636}….(一部抜粋)
実行してみると、上記のようなメッセージが出力されました。日本語では出力されない。
今回は日本語のレシートをスキャンしてみましたが、Amazon Textract で検出と抽出できるテキストは、英語、スペイン語、イタリア語、フランス語、ポルトガル語、ドイツ語しか、2022年4月現在は対応していない。
よって、日本語の検出と抽出はできない。今後、対応される可能性はあるが、いつかは不明である。

コメント