
PythonでFirebaseCloudFirestoreに追加したデータを読み取ってみます。
前回、PythonでFirebaseCloudFirestoreを使用するという記事を公開しましたが、その続きで追加したデータを読み取ってみます。
なお、データを読み取るためには、Firebase AdminSDKのライブラリをインストールする必要があります。
■PC環境
Windows 10 Pro
■Python

今回のPythonのバージョンは、「3.8.5」を使用しています。(Windows10)(pythonランチャーでの確認)
■FirebaseCloudFirestoreに追加したデータを読み取る
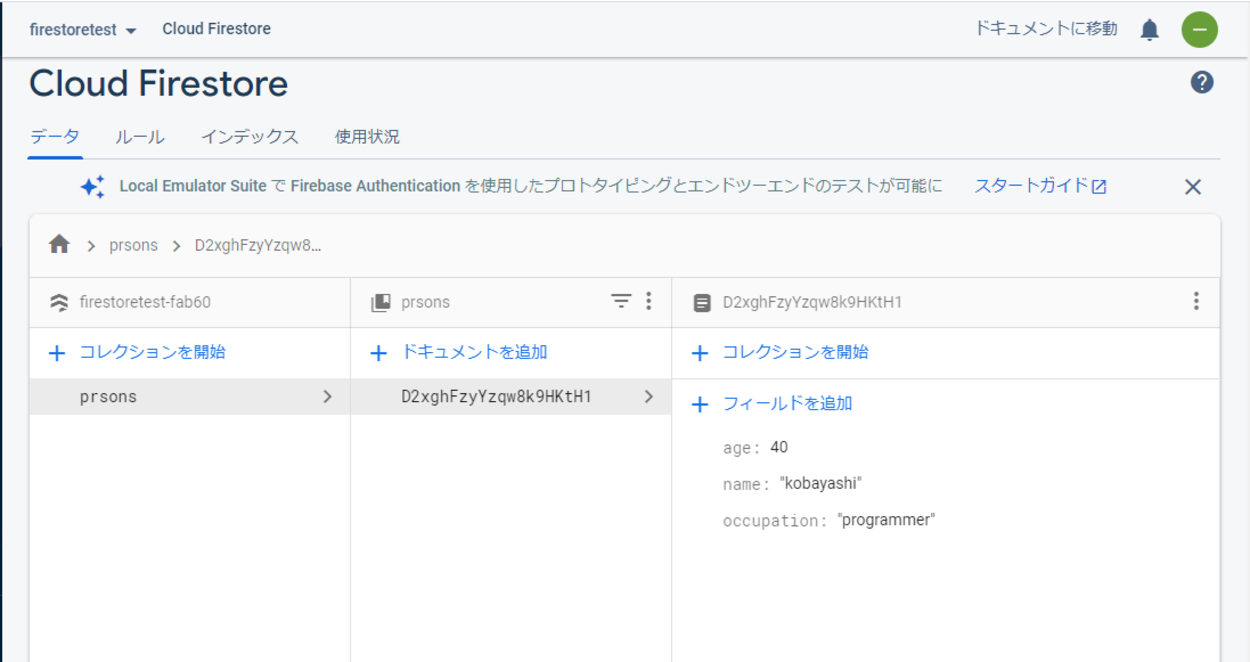
Cloud Firestoreで、今回は上記のように、「prsons」というコレクションを作成し、その中にデータ(フィールド)を追加しています。
追加したデータ(フィールド)を、Pythonを使用し、読み取ってみます。
■コード
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
cred = credentials.Certificate(r"firestoretest-fab60-firebase-adminsdk.json(生成された秘密鍵・JSONファイル)")
firebase_admin.initialize_app(cred)
db = firestore.client()
result = db.collection('prsons').document("D2xghFzyYzqw8k9HKtH1").get()
if result.exists:
print(result.to_dict())追加したデータ(フィールド)を読み取る場合は、resultという変数を作成し、その中で作成したデータベース(db変数)に対して、collection()関数を使用し、「prsons」という作成したコレクションを渡します。その後、document()を使用し、コレクションの中に作成されたドキュメント「D2xghFzyYzqw8k9HKtH1」を渡します。最後にget()を使用します。これで、作成したコレクション内のドキュメントにあるデータ(フィールド)を取得し、変数に格納することができます。
格納後、if文を使用し、result変数内のデータの存在の有無を判定し、もしTrue(真),条件を満たす場合であれば、to_dict()関数で、result変数内のデータを辞書に変換し、print()関数で出力します
■実行(検証)
このスクリプトを「database_read.py」という名前で保存し、コマンドプロンプトから実行してみます。
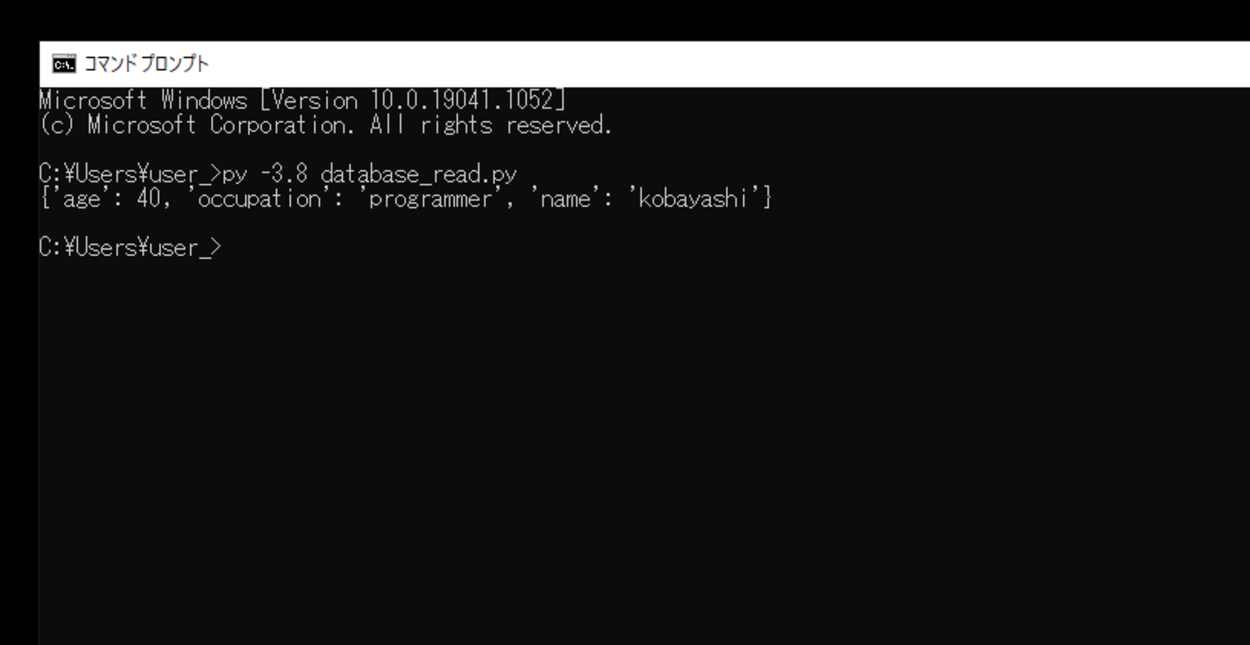
実行してみると、サービス アカウント(生成された秘密鍵・JSONファイル)を使用し承認が行われ、作成したコレクションにアクセスし、ドキュメントに追加されたデータ(フィールド)を取得し、print()関数で出力することができました。
■コレクション内のすべてのドキュメントを取得する(読み取る)
では、次にコレクション内のすべてのドキュメントを取得してみます。(読み取る)
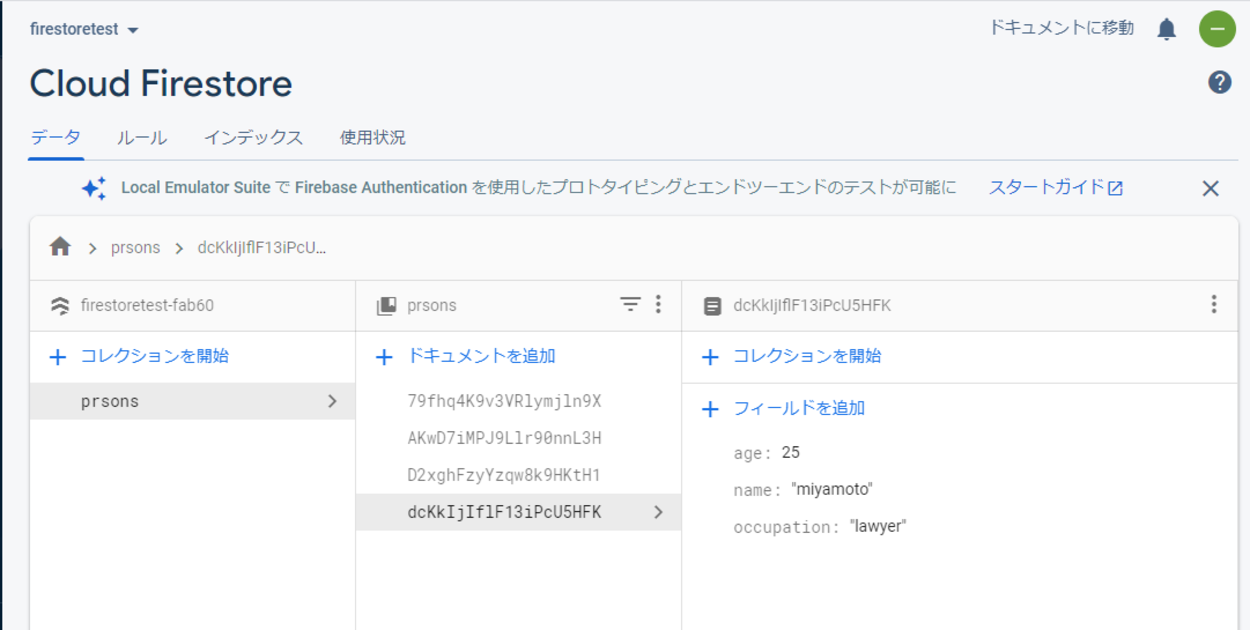
取得する前に、コレクション内に複数のドキュメント,フィールドを追加しておきます。
■コード
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
cred = credentials.Certificate(r"firestoretest-fab60-firebase-adminsdk.json(生成された秘密鍵・JSONファイル))
firebase_admin.initialize_app(cred)
db = firestore.client()
docs = db.collection('prsons').get()
for doc in docs:
print(doc.to_dict())コレクション内のすべてのドキュメントを取得する(読み取る)際は、docsという変数を作成し、その中で、作成したデータベース(db変数)に対してcollection()関数を使用し、「prsons」という作成したコレクションを渡します。その後、get()を使用します。これで、コレクション内のデータ(ドキュメント,フィールド)が全て取得され、変数に格納されます。
格納後、for文によるループ処理(繰り返し処理)で、docs変数に格納されたコレクション内のデータ(ドキュメント,フィールド)を、to_dict()関数で辞書に変換し、print()関数で出力します。
■実行(検証)
このスクリプトを「database_read_2.py」という名前で保存し、コマンドプロンプトから実行してみます。
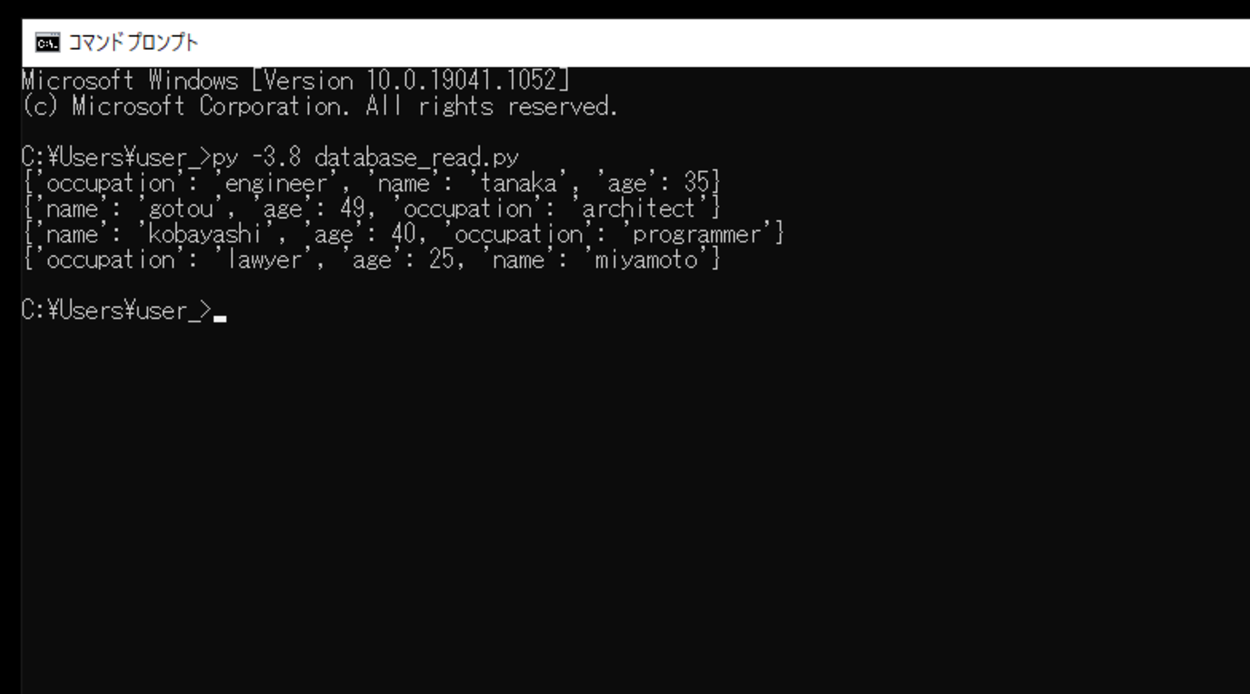
実行してみると、サービス アカウント(生成された秘密鍵・JSONファイル)を使用し承認が行われ、作成したコレクションにアクセスし、コレクション内のすべてのドキュメントを取得。取得後、for文とprint()関数ですべてのドキュメントを出力させることができました。この時、ドキュメント内のフィールドも出力となります。

コメント