
Pythonでtabulateモジュールを使用しテーブル(表)のHTMLコードを抽出してみます。
tabulateモジュールは、Pythonの標準ライブラリとなっていますので、事前にインストールする必要はありません。
■Python
Google Colaboratory(Google Colab),Python3.7.10
■tabulateモジュールを使用しテーブル(表)を作成
まずは、tabulateモジュールを使用し、テーブル(表)を作成してみます。
■コード
from tabulate import tabulate
all_data = [["番号","名前","年齢"],
[1,"山田",19],
[2,"西岡",23],
[3,"朝比奈",25],
[4,"和泉",29],
[5,"川島",45]]
table1 = tabulate(all_data)importでtabulateモジュールを呼び出します。その後に今回はall_dataという変数を定義し、その中で角括弧( [ ] )を使用しリスト(配列)を作成し、格納します。
その後、table1という変数を定義し、その中でtabulate()関数を使用します。tabulate()関数の括弧内には、引数,パラメータとして、all_data変数を渡します。これでテーブル(表)が作成されます。
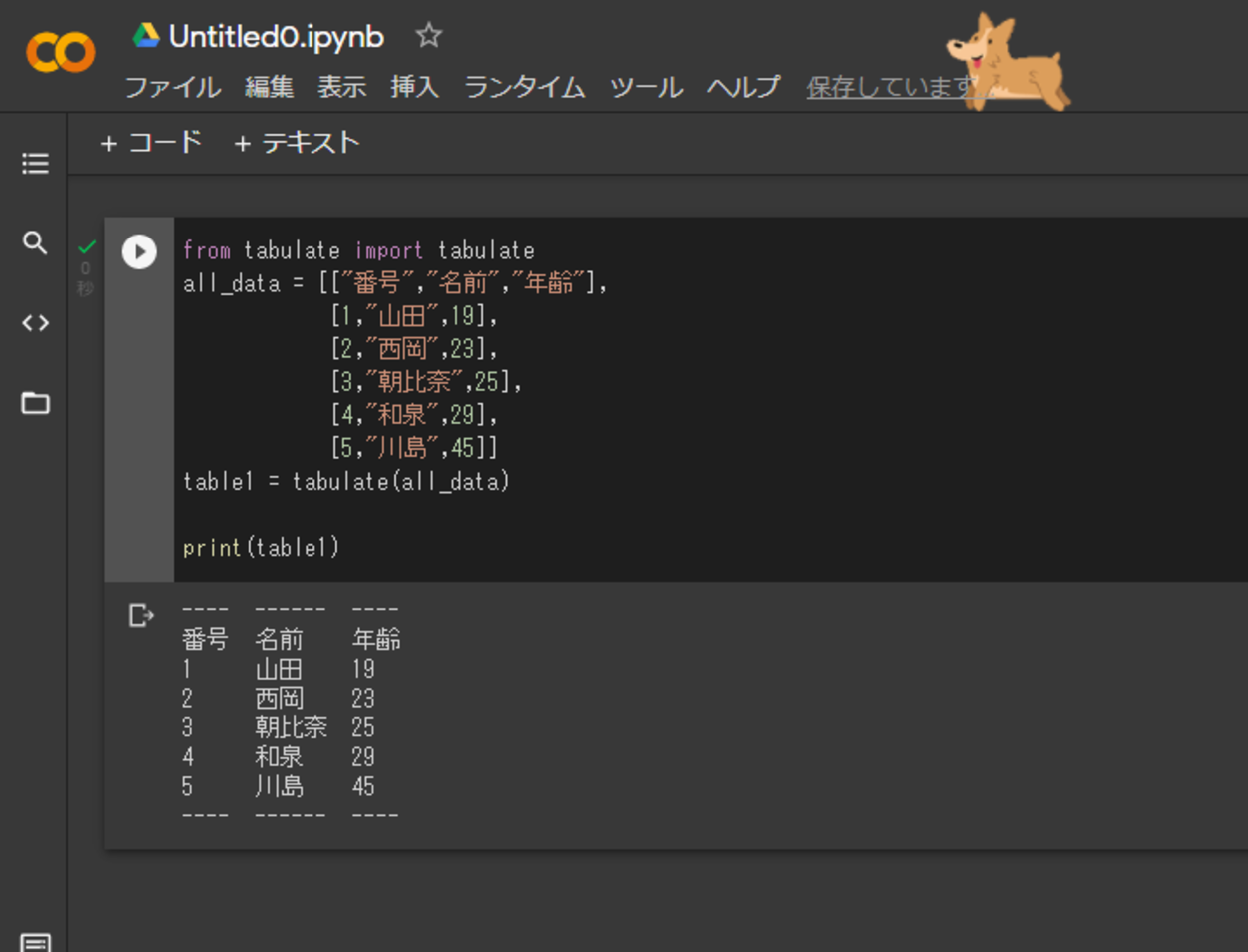
print()関数で出力すると上記のように出力されます。
■テーブル(表)のHTMLコードを抽出する
出力後、作成したテーブル(表)のHTMLコードを抽出してみます。
■コード
from tabulate import tabulate
all_data = [["番号","名前","年齢"],
[1,"山田",19],
[2,"西岡",23],
[3,"朝比奈",25],
[4,"和泉",29],
[5,"川島",45]]
print(tabulate(all_data,tablefmt='html'))抽出する場合は、tabulate()関数を使用する際に、括弧内に「tablefmt=」と記述し、tablefmt属性を設定します。設定の際に「html」を設定するので、引数,パラメータとして渡します。これで、HTMLコードを抽出することができます。
■実行
このスクリプトを実行してみます。

実行してみると、tabulate()関数を使用したことで、all_data変数内のリスト(配列)を元にテーブル(表)が作成され、さらにHTMLコードを抽出(生成)。抽出(生成)されたHTMLコードをprint()関数で出力させることができました。

コメント